
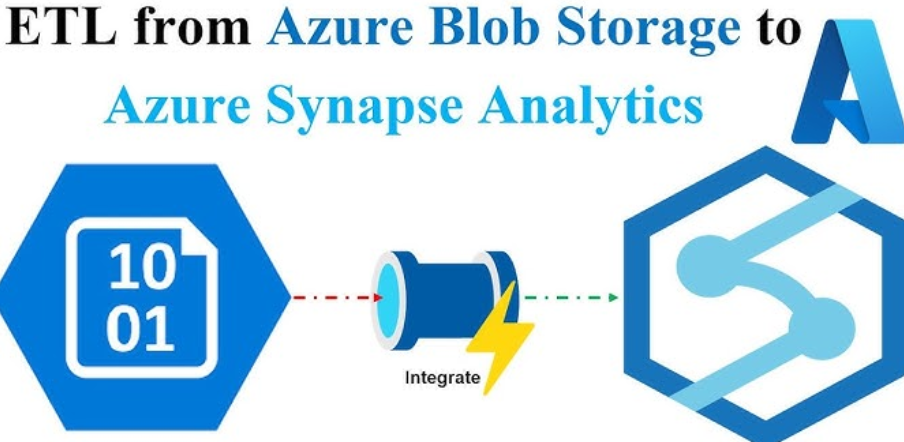
It is inherently difficult to train or document how to troubleshoot technical problems because of the wide variety of symptoms one is exposed to. That means when an example is used to teach troubleshooting, it will most likely not be one that the person being trained will experience. Instead, there are two points to make concerning troubleshooting. The first one is that technical problems, from an application‐level perspective, come in three forms: exceptions, slowness, and unavailability. You can troubleshoot each type of problem by using the information you learned in the Chapter 9. As shown in Figure 9.16, stdout logging is useful for observing the output of an Apache Spark job. As shown in Figure 10.15, you can use stderr logging to render exceptions that are generated within the job.
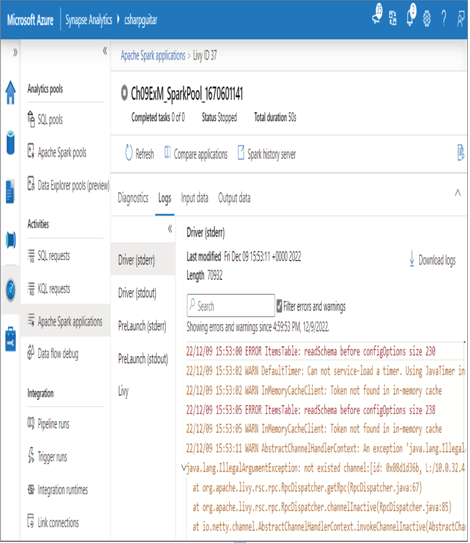
FIGURE 10.15 Troubleshooting a failed Spark job: stderr
The exception message can be helpful to determine the reason for the exception and trigger some ideas for how to avoid and correct the issue. From a slowness perspective, there are two areas you need to analyze. The first area is the source code the job is executing. You need to determine if there are any bad coding patterns, such as recursion, imbedded loops (aka loops within loops), or any of the patterns stated in Table 10.1. There second area is the resource consumption of the Apache Spark cluster or pool that was consumed during the job execution, as shown in Figure 9.21, which illustrates network, CPU, and memory consumption for the Apache Spark cluster that ran the job. There is a similar set of metrics for the Apache Spark pool when the job is run from the Azure Synapse Analytics workspace, as discussed in the “Monitor Cluster Performance” section of Chapter 9. Both platforms, Azure Databricks and Azure Synapse Analytics, have autoscaling capabilities. When you created the Azure Databricks workflow in Exercise 6.8, you were instructed to set the number of workers to one and not enable autoscaling. This was done to reduce costs as you were testing and learning, and it is necessary to make sure compute is not consumed unnecessarily or accidentally. However, in a production scenario where you know that you may need extra capacity, you can enable autoscaling, as shown in Figure 10.16.
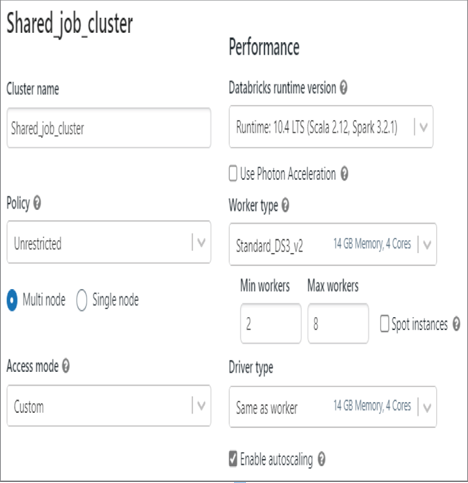
FIGURE 10.16 Troubleshooting a failed Spark job: scaling Apache Spark workflow cluster
Checking the Enable Autoscaling check box increases the Min Workers value to 2 and the Max Workers value to 8. You can modify both values to allow an increase/decrease of the minimum workers and increase/decrease the maximum number of workers the cluster can be scaled to. Each node in the cluster will contain the compute resources identified in the Worker Type drop‐down list box. Apache Spark pools in Azure Synapse Analytics have the same runtime capability for determining the worker size as they do for a data flow. The following expression sets the Executor Size value to Large when the size value from the GetAKVMonitorLog activity is greater than 100 MB; otherwise, set the Executor Size to Small. Figure 10.17 shows the configuration.
@if(greater(activity(‘GetAKVMonitorLog’).output.size, 100000000), ‘Large’, ‘Small’)
Also notice the Dynamically Allocate Executors option. When this option is enabled, the platform will add additional nodes with compute resources identified by the Execute Size value, as required.
The final technical issue has to do with availability. If one or more of the dependencies the job relies on is not online or has crashed, then the job will time out and fail. The reasons for this occurrence are many, such as a newly implemented firewall rule, a breach in the threshold of DTUs for a database, an unhandled exception in a system process, a power outage in the datacenter, or an update to the user ID and password. The fact that the job cannot access a dependent resource will result in an exception, and the exception will provide a message. From that point, you need to act based on the specific resource that is not accessible. The resolution could be as simple as a reboot.
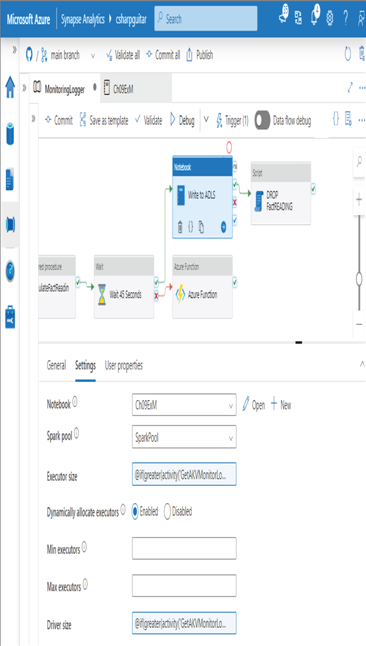
FIGURE 10.17 Troubleshooting a failed Spark job: scaling Apache Spark pool job