

Exceptions will have major impact on performance, even if handled, so you should log them, set up alerts when they happen, and work toward avoiding them all together.
Chapter 6, “Create and Manage Batch Processing and Pipelines,” introduced the different execution paths (aka conditions) that can be taken between pipeline activities. As shown in Figure 6.28, the four options are Success, Failure, Completion, and Skipped. You also saw the execution paths in Figure 6.64 and Figure 6.65, which were part of Exercise 6.13, and Figure 6.72. As a discussion point, note in Figure 10.24 the failure dependency between a data flow named AzureSQL and a Script activity named DROP FactReading. There is also a failure dependency between the SQL pool stored procedure activity named PopulateFactReading and the DROP FactReading Script activity.
The behavior is that if either AzureSQL or PopulateFactReading fail, then DROP FactReading will be executed. If that activity is completed successfully, then the pipeline will report a Success status. Alternatively, if there was no failure condition from either of those two activities and either of them failed, then the pipeline would report a Failed status. A failed pipeline execution should trigger an alarm that would engage humans to investigate and fix the problem. Getting a person to troubleshoot a failed pipeline is an expensive process. You could instead handle the error. Handling the error requires application knowledge. That means you would need to know what AzureSQL and PopulateFactReading do and what their dependencies are. AzureSQL basically copies brain wave data from an AzureSQL database to a database on a dedicated SQL pool. If either of those databases is not available or the copy fails, then in this context you would not want any data analytics performed on the table named FactREADING. The PopulateFactReading activity executes the stored procedure named uspCreateAndPopulateFactReading, which you applied within Exercise 5.1. The code is in the Chapter05/Ch05Ex01 directory on GitHub. The SQL in the stored procedure expects that the table named FactREADING does not exist. If the table does already exist, then the attempt to create it will fail, which is why there is a failure dependency with an activity that drops that table. Changing the code in the stored procedure might be a better option than implementing error handling; however, making changes to product code is risky and requires a lot of testing and approvals. The first of two benefits of the failure condition is that it prevents the pipeline from returning a Failed status, which triggers support. The second benefit is that it enables you to clean up data that might prevent the next run on the pipeline from completing successfully. You might be thinking, if this is implemented, then the pipeline could be failing but reporting successful, and no one would know. That would be true had you not learned about monitoring, logging, and alerting in the Chapter 9. You would want to be sending Error logs to an Azure Monitor Log Analytics cluster and alerting when errors are happening.
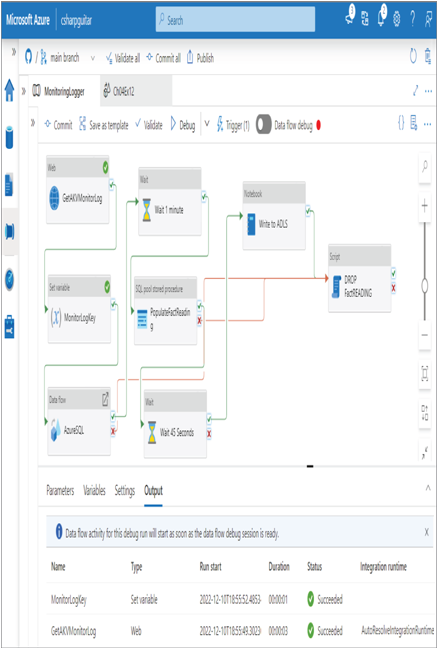
FIGURE 10.24 Troubleshooting a failed pipeline run: dependency conditions
The final point has to do with retrying and rerunning data flows and pipelines. It is common to retry or rerun processes when there is an unexpected error, as previously mentioned. The important point is that you need to make sure the data is in the expected state for further ingestion and transformation. If an error results in the stopping of a pipeline or Data Flow activity, then you need to check the data to make sure it was not corrupted, since the operation being run on it did not complete as expected. As shown in Figure 10.25, there are options that apply to a Data Flow activity to configure the number of retry attempts and the retry interval. A value of 5 for the Retry property instructs the data flow engine to attempt the execution of the activity five times before returning a status result of Failed to the pipeline. The value of 120 for Retry Interval causes the engine to wait 2 minutes between each retry.
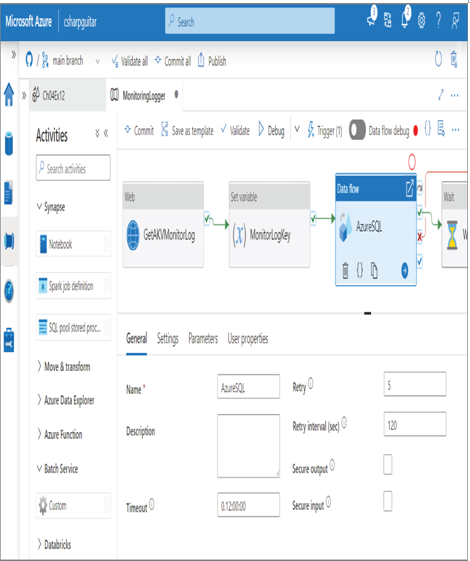
FIGURE 10.25 Troubleshooting a failed pipeline run: retries
From a pipeline perspective there are two methods to trigger a rerun. The first is to simply wait until the next scheduled trigger to fire. If this is not an option, then notice the three options in Figure 10.26 named Rerun Entire Data Pipeline, Rerun From Selected Activity, and Rerun From Failed Activity.
The option names provide good clues about their purpose. Notice first that the pipeline did report a Failed status, because there is no failure dependency from the AzureSQL activity in this pipeline example. Next, notice that the Set Variable activity named MonitorKeyLog is highlighted and is the activity appended to the Run From activity button. That means you would select the activity from the point where you want to rerun the pipeline. In this case, there is no need to rerun the first activity, as the results of it are still available as input into the second activity, MonitorKeyLog. The other option is to not select any activity and rerun the pipeline from the point of failure—in this case, the Azure SQL activity.
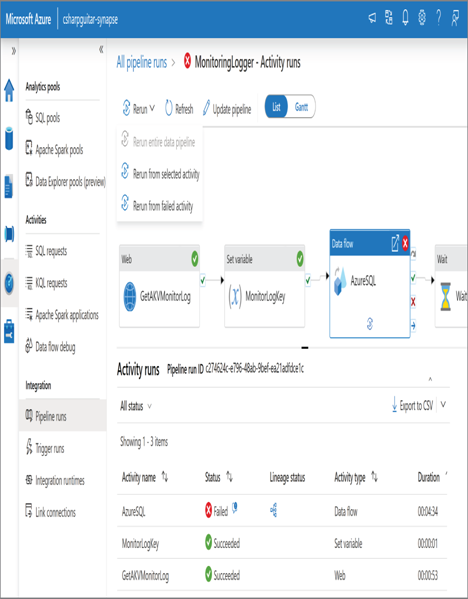
FIGURE 10.26 Troubleshooting a failed pipeline run: reruns