

Figure 6.6 shows the select node size when you provisioned your Azure Batch pool. Notice that the Mode toggle switch is set to Fixed, with a targeted dedicated nodes value of 2. This means the amount of compute capacity allocated to this pool is fixed and will not scale. If the utilization of the allocated resource reaches 100 percent, then the jobs will either screech to a halt or run very slowly. The alternative to Fixed mode is Auto Scale, which can be changed after the pool is provisioned. There is a Scale navigation item and a Scale menu link on the Overview blade in the Azure portal for the Azure Batch pool. Clicking the Scale button and then enabling the Auto Scale toggle switch renders the blade shown in Figure 10.28.
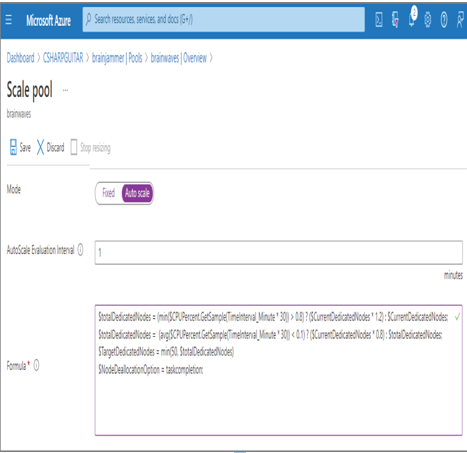
FIGURE 10.28 Scaling resources: Azure Batch pool
As shown in Figure 10.28, scaling is managed with an autoscale formula. The first snippet sets the number of nodes based on a sampling of CPU consumption. The CPU sample time frame is 30 minutes, which is 30 multiplied by the value of the AutoScale Evaluation Interval setting, which in this case is 1. If the CPU percentage is over 80 percent, increase the current number of nodes by 20 percent; otherwise, leave the current number of nodes as they currently are. The variable named totalDedicatedNodes is a service‐defined variable, and making a change to it results in the platform taking an action on its change.
$totalDedicatedNodes =
(min($CPUPercent.GetSample(TimeInterval_Minute * 30))> 0.8) ?
($CurrentDedicatedNodes * 1.2) : $CurrentDedicatedNodes;
It is important to scale back down when capacity is no longer needed. When you scale up, those nodes will remain allocated and generate cost regardless of whether they are utilized or not. The platform does not make any conclusions about whether your batch job requires more or less compute capacity; you must manage this completely, scaling down as necessary. The following snippet checks the CPU percentage every 30 minutes. If the result is less than 10 percent CPU consumption, then the number of nodes will be scaled down by 80 percent. It is important to not scale down too quickly, and you need to keep the scale‐up and scale‐down thresholds as far apart as possible. There is a concept called flapping, where scale‐up and scale‐down rules overlap, which causes unexpected behaviors. It does take some time to get jobs running on a new node. If the scale‐up and scale‐down rules are too close together, a scale command could be triggered during this lag time and cause some issues.
$totalDedicatedNodes =
(avg($CPUPercent.GetSample(TimeInterval_Minute * 30)) < 0.1) ?
($CurrentDedicatedNodes * 0.8) : $totalDedicatedNodes;
It is also good practice to manage the maximum number of nodes the platform will scale out to. If a rogue job gets started and consumes large amounts of CPU, you could receive a very large bill. You must pay for those things in the cloud because your code consumed the compute whether you meant it to or not. The following snippet will restrict the platform to scaling out to a maximum of 50 nodes:
$TargetDedicatedNodes = min(50, $totalDedicatedNodes)
To prevent a scale‐down procedure from happening until all the tasks are completed on the node, add the following snippet:
$NodeDeallocationOption = taskcompletion;
Lastly, note that there is no option to increase the node size after the pool has been provisioned. You can increase the number of nodes only. If it is determined that you need to increase the VM sizes, you will need to provision a new pool.