

The description of user‐defined functions (UDF) in Chapter 2 is very informative, so have a look back at it if you need a refresher. In general terms, a UDF is a code snippet that performs some action on your data. These code snippets are most commonly triggered using the method name from within either SQL queries or stored procedures. One benefit of a UDF is that it reduces the amount of written code necessary to perform actions. This was the example from Chapter 2. Another benefit is that you can validate or format data. The result of the SQL query from Chapter 2 displays the values with three decimal points, as follows:
SELECT * FROM ValuesByFrequency (1)
+——————+————-+————-+————+
| SCENARIO | ELECTRODE | FREQUENCY | VALUE |
+——————+————-+————-+————+
| ClassicalMusic | AF3 | THETA | 4144.103 |
| PlayingGuitar | AF4 | THETA | 26.250 |
| TikTok | AF3 | THETA | 9.681 |
| … | … | … | … |
+——————+————-+————-+————+
If you want to rewrite the UDF so that only two decimals are rendered, you would execute the following SQL command, which alters the UDF:
ALTER FUNCTION ValuesByFrequency (@frequencyid int)
RETURNS TABLEASRETURN
( SELECT TOP 10 sc.SCENARIO, e.ELECTRODE, f.FREQUENCY,
CAST(ROUND([VALUE],2,4) AS DECIMAL(19,2)) AS [VALUE]
FROM SCENARIO sc, [SESSION] s, ELECTRODE e, FREQUENCY f, READING r
WHERE sc.SCENARIO_ID = s.SCENARIO_ID
AND s.SESSION_ID = r.SESSION_ID
AND e.ELECTRODE_ID = r.ELECTRODE_ID
AND f.FREQUENCY_ID = r.FREQUENCY_ID
AND f.FREQUENCY_ID = @frequencyid)
When you then use the rewritten UDF by executing the following SQL statements, the resulting data in the VALUE column will be rounded to two decimal places. The results of the query follow the snippet. The ALTER statement and the SQL query are in the Chapter10 folder on GitHub, in a file named alterUDF.sql.
SELECT * FROM ValuesByFrequency (1)
+——————+————-+————-+———–+
| SCENARIO | ELECTRODE | FREQUENCY | VALUE |
+——————+————-+————-+———–+
| ClassicalMusic | AF3 | THETA | 4144.10 |
| PlayingGuitar | AF4 | THETA | 26.25 |
| TikTok | AF3 | THETA | 9.68 |
| … | … | … | … |
+——————+————-+————-+———–+
In Chapter 3, you learned about functions with regard to Azure Stream Analytics. Specifically, you read about JavaScript UDFs with an example like the following, which returns the square root of the number passed as a parameter:
function squareRoot(n) {return Math.sqrt(n);}
To change or rewrite this UDF, access it via the portal and make the change, similar to that shown in Figure 10.27.
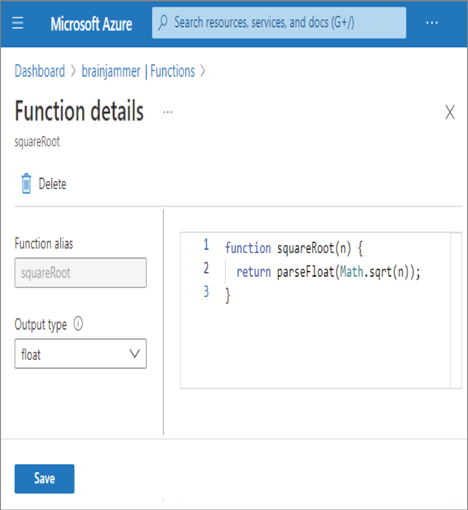
FIGURE 10.27 Rewriting Azure Stream Analytics user‐defined functions
Making the change is not so complicated. Keep in mind that you would not want to make this change directly to your production data analytics pipeline. This would also require functional and regression testing prior to moving into a live environment. This also applies to the changes made to the SQL function, as it does to the following UDF contained in a notebook that runs on an Apache Spark cluster. In Exercise 5.10 you wrote the following UDF:
unlist = udf(lambda x: round(float(list(x)[0]),3), DoubleType())
The UDF helped in the process of normalizing brain wave data from the disbursement shown in Figure 5.29 to a more normalized form, as shown in Figure 5.30. Making a change to this is the same as proposed in the previous example. This is achieved by opening the notebook named Ch05Ex10 and performing the update. Once you complete the local testing, make the commits and have the modification flow through your release management process.