

While working as a DevOps specialist a few years ago, I was tasked with helping developers in my team to ship features faster. Upon understanding the challenges they faced in the huge monolithic LAMP stack (Linux, Apache, MySQL, and PHP) application, MySQL surfaced as a common pain point across the board. The continuously increasing size of these on-premises production databases (1 TB+) meant that the developers were frequently unaware of the challenges the application would face in the live environment when the production load kicked in. The application (warehouse management system) was used across several countries in Europe, with each country having its own dedicated MySQL
| AWS and DevOps – a perfect match | 5 |
instance and read replicas. Every minute of downtime or system degradation directly impacted shipping, packaging, and order invoicing. During that time, the developers were using local MySQL instances to develop and test new features and would later ship them off to staging, followed by production rollout.
With the problem statement clear, a promising next step was to enable them to develop and test in production-like environments. This would allow them to see how their systems were reacting to evolving customer usage, and to have a better understanding of the production issues at an earlier stage.
With a strong understanding of Bash scripting (…or at least I thought so) and basic MySQL administration skills, I decided to build shell scripts that could prepare these testbed environments, and refresh them with the most recent production data, on a daily basis. A request for a similar number of new MySQL servers was raised with the on-premises infrastructure team. They provisioned them in a week, set up the operating system, and required libraries for MySQL, before handing over to me my newly acquired liability. Moving forward, all maintenance and upkeep of these servers were my responsibility. I laterscheduled cronjobs on all these servers to run the scripts created previously. They would perform the following steps at a pre-configured time of the day:
- Copy the previous day’s production backups from the fileserver to the local filesystem.
- Remove all existing data in the local MySQL database.
- Dump the new backup data into the local MySQL database.
- Perform data anonymization and remove certain other confidential tables.
You can see how the different entities communicated in the following figure:
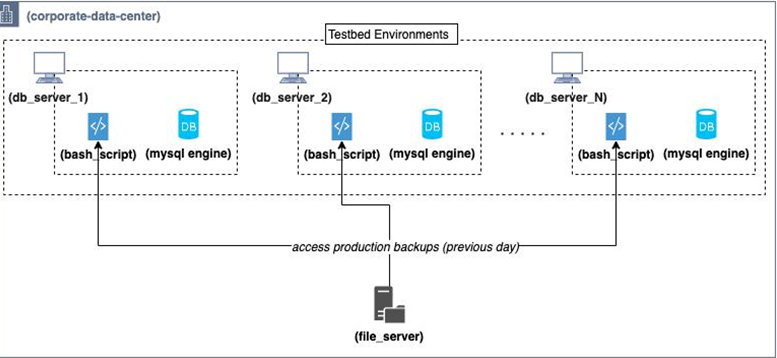
Figure 1.1: Bash scripts to manage database operations
The following day, the developers had recent production replicas available at their disposal, anonymized for development and testing. This was a huge step forward and the developers were excited about this as they were now developing and testing against environments that matched production-level scale and complexity. The excitement, however, was soon overshadowed by new issues. What happens if a particular cronjob execution does not terminate successfully? What if database import takes forever? What if fileservers are not responding? What if the local storage disk is full?
How about a parent orchestrator script that manages all these edge cases? Brilliant idea! I spent the next few days building an orchestrator layer that coordinated the execution of all these scripts. It was not too long before I had a new set of Bash scripting problems to solve: tracking child process executions, exception handling, graceful cleanups, handling kernel signals…the list goes on. Doing all this in Bash was a Herculean task. What started as a simple set of scripts now evolved into a framework that required a lot of investment in time and effort.
Days and weeks passed, and the framework kept evolving. Bugs were identified. New feature requests from the developers were implemented. The framework now had a fancy new name: Bicycle – end-to-end life cycle management for Bash scripts. Finally, after two months, a YAML config-driven Bashframework came into being that sent error notifications on Slack, executed report attachments via email, orchestrated and measured the entire flow of operations, and was generic enough to be adopted by other teams easily. This was not solely for managing database operations, but rather anycollection of Bash scripts put together to accomplish a task, as you can see in Figure 1.2:
Figure 1.2: Bicycle framework – managing the life cycle of Bash scripts
The framework served the team well for two to three weeks and then the next wave of challenges became evident:
- Data import time was increasing exponentially. To execute parallel MySQL threads, I needed more compute power – so, another request to the infrastructure team was needed.
- High I/O operations required more performant disks. To upgrade these, the infrastructure team had to raise a new purchase order and install new SSDs.
- Developers now wanted the capability to be able to maintain the latest X versions of the backups. Where should these be stored?
As you might have noticed already, the framework had matured considerably, but it was as good as the availability, scalability, and reliability of the underlying infrastructure. With underpowered machines, disk capacity issues, and frequent network timeouts, there was only so much the framework could do.
What started as an initiative to increase development velocity soon transitioned into a technology-focused framework. Were there some technical learnings from this exercise? A lot. In fact, there were so many that I wrote a Best Practices for Bash Scripts blog afterward, which can be found at https:// medium.com/p/17229889774d. Did it resolve all the problems the developers were facing? Probably not. Before embarking on these lengthy development cycles and going down the rabbit hole of solving technical problems, it would have been better to build a little, test a little, and always challenge myself with the question, Is this what my customers really need?