
An interruption to the processing of your data stream flowing through your Azure Stream Analytics job can occur in many forms. One of the most catastrophic examples is caused by an event such as a storm or other event that results in the closure of all datacenters in a given Azure region. Although these events are considered extremely rare, some businesses run such critical business applications that continue to operate under extreme circumstances. For example, medical, police, communication, and transportation services must operate in emergencies and need their applications to continue to run.
Chapter 4 introduced BCDR, which is the recovery plan created ahead of time that should be followed when the situation dictates. The plan outlines the transfer of your operations from one region to another, for example, from West Europe to North Europe or from East US to West US, both of which represent paired Azure regions. Refer to Table 4.2 for more examples of paired Azure regions. When an entire region is offline, you will need to provision an identical replica of the environment you had in the offline region. Having this replica environment provisioned in advance and keeping it updated with your data will result in a faster recovery from an event like this. Recognize, however, that this can come with a significant cost. Having this standby environment is dependent on the degree of importance of that application and the impact should it be unavailable. If the impact is great, then the cost is justifiable. If not, an alternative may be to have the scripts ready to provision the infrastructure as a temporary solution. Then, once the primary production environment is back online, redirect users back to the original environment and move the data created during the outage.
Another type of interruption can occur when a single datacenter in the region goes offline. This form of interruption is resolved by availability zones, which are isolated datacenters in a region, as introduced in Chapter 1. Many Azure products, such as Azure Event Hubs, are automatically replicated into multiple datacenters to manage occurrences of this specific kind of scenario. If the situation arises that necessitates the redirection of traffic from one zone to the other, it will be managed for you. There would be some transient impact; however, that momentary disruption is much less than being totally offline for a longer period of time.
At the time of this writing, an Azure Stream Analytics job, as you created in Exercise 3.17, does not support availability zones. To gain zone replication for an Azure Stream Analytics job, you must provision your own cluster. Configuring and managing an Azure Stream Analytics cluster is not covered in this book. Briefly, that product provisions a dedicated amount of compute resources that can be used to run all your jobs. This contrasts with the job created in Exercise 3.17, where each job is on a multitenant cluster. To view or change this, navigate to the Environment blade in the Azure portal, change the configuration to Dedicated, and then provision the cluster, as shown in Figure 10.29.
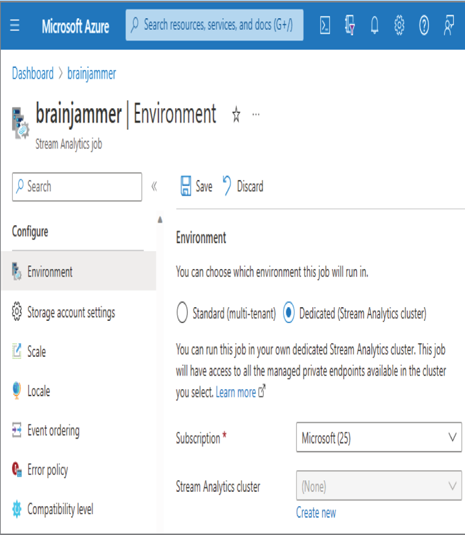
FIGURE 10.29 Handling interruptions: dedicated Azure Stream Analytics cluster
If you require zone replication, then you must provision an Azure Stream Analytics cluster; otherwise, you will need to have a BCDR plan that includes the provisioning of the job in a paired region. The other form of interruption was the one touched on in Chapter 7, which concerned node failure, OS updates, and product upgrades. If the node your job is running on is identified as being unhealthy, the platform will take an action to rehost your job on another instance. A massive amount of telemetry is generated and monitored on the Azure platform that is used for managing and taking actions when servers are identified as being unhealthy, so you do not need to worry much about that. The same goes for OS and product updates, especially when your job spans across availability zones. Upgrades of these kinds are rolled out strategically to avoid causing downtime. Consider a situation in which your job is in three zones and an OS patch needs to be applied. The platform will do its best to not install the upgrade onto nodes in the different zones that host the same job at the same time. This results in the endpoint being available to ingest, transform, and output data even when updates are being applied. The final form of interruptions is focused on the application itself, which has to do with bottlenecks and resource consumption. In that scenario, you might need to add additional compute resources to the job, as covered in the next section.